CEEC Progress Towards More Energy-Efficient CFD
Energy efficiency is an emerging central challenge for modern high-performance computing (HPC) systems, where escalating computational demands and architectural complexity lead to significant energy footprints. Below is a presentation of our experience measuring, analyzing, and optimizing energy consumption across major European HPC systems. Through case studies using representative CFD applications waLBerla, FLEXI/GALÆXI, Neko, and NekRS, we evaluate energy-to-solution and time-to-solution on diverse architectures, including CPU- and GPU-based partitions of LUMI, MareNostrum5, MeluXina, and JUWELS Booster. Our results highlight the advantages of accelerators and mixed-precision techniques for reducing energy consumption while maintaining computational accuracy.
Although this content was originally designed as a poster for display at EuroHPC Summit 2026 in Cyprus, this event is unfortunately postponed indefinitely. We hope that this blog post can act as at least a small substitute for the lost opportunities for knowledge exchange.
Lighthouse Case Codes
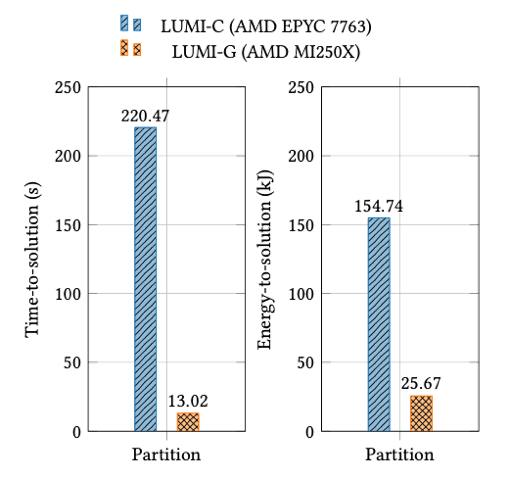
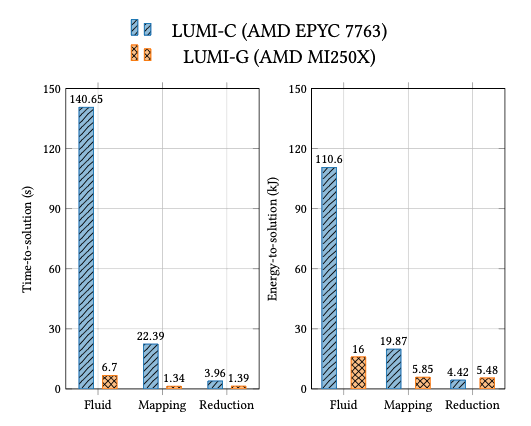
Within the scope of the CEEC project, the waLBerla multiphysics framework is employed to develop a fully resolved, coupled fluid-particle numerical model, referred to as lighthouse case 4 (LHC4). This model is designed to investigate the phenomenon of piping erosion, which poses a significant threat to geotechnical structures such as offshore wind turbine foundations and dams. waLBerla demonstrates clear benefits of GPU acceleration for coupled fluid–particle simulations when evaluated using node-level SLURM energy measurements. On LUMI, GPU nodes significantly reduce both time-to-solution and energy-to-solution compared to CPUs. The study also reveals kernel-dependent behavior: while most components favor GPUs, certain reduction operations remain comparatively energyefficient on CPUs, highlighting the importance of fine-grained energy analysis.
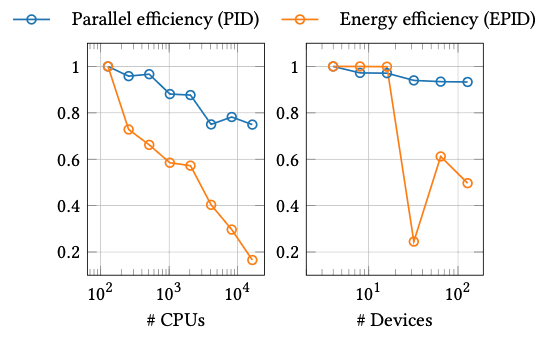
In the context of CEEC, the open-source, high-order accurate flow solver FLEXI and its GPU counterpart GALÆXI are utilized to examine the shock buffet on a 3D wing under transonic flight conditions, referred to as lighthouse case 1 (LHC1). Shock buffet leads e.g. to increased structural fatigue of the wing in the long run, and thus has implications for aircraft safety and efficiency. Energy measurements for FLEXI/GALÆXI across multiple European systems show that GPUs consistently outperform CPUs in energy-to-solution, when the simulation is large enough to provide sufficient workload per device. Using the EPID (the energy normalized performance index) and energy ratio metrics, the study reveals that energy efficiency degrades faster than parallel efficiency at scale, especially on CPUs. GPU partitions deliver superior energy efficiency and runtime, emphasizing the need for workload-aware scaling and accelerator-centric design in high-order discontinuous Galerkin solvers.
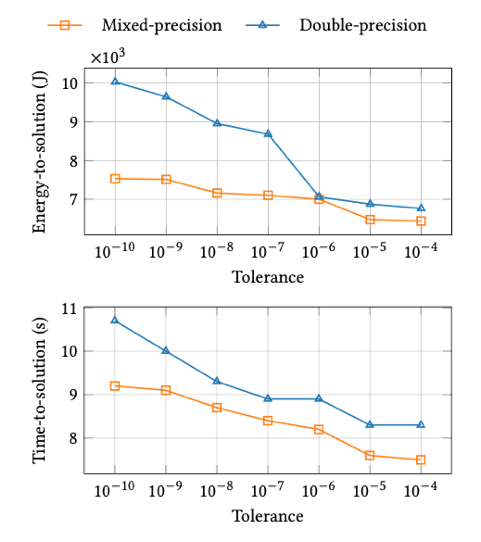
Neko is a portable simulation framework based on high-order Spectral Element Methods (SEM) on hexahedral meshes, mainly focusing onincompressible flow simulations. In this mixed-precision study, we focuson solving the Poisson equation for pressure, one of two equations, in the Navier-Stokes equation using the preconditioned Conjugate Gradient(PCG). For Neko, energy measurements collected with the EnergyAware Runtime (EAR) highlight the strong potential of mixed-precisionsolvers to reduce energy consumption. By relaxing solver tolerances and combining mixed precision with spectral element discretization,Neko achieves lower energy-to-solution and faster runtimes by up to1.3x compared to double precision. The results demonstrate a direct link between numerical accuracy requirements, solver configuration, and energy efficiency, supporting adaptive precision as a key strategy for sustainable CFD simulations.
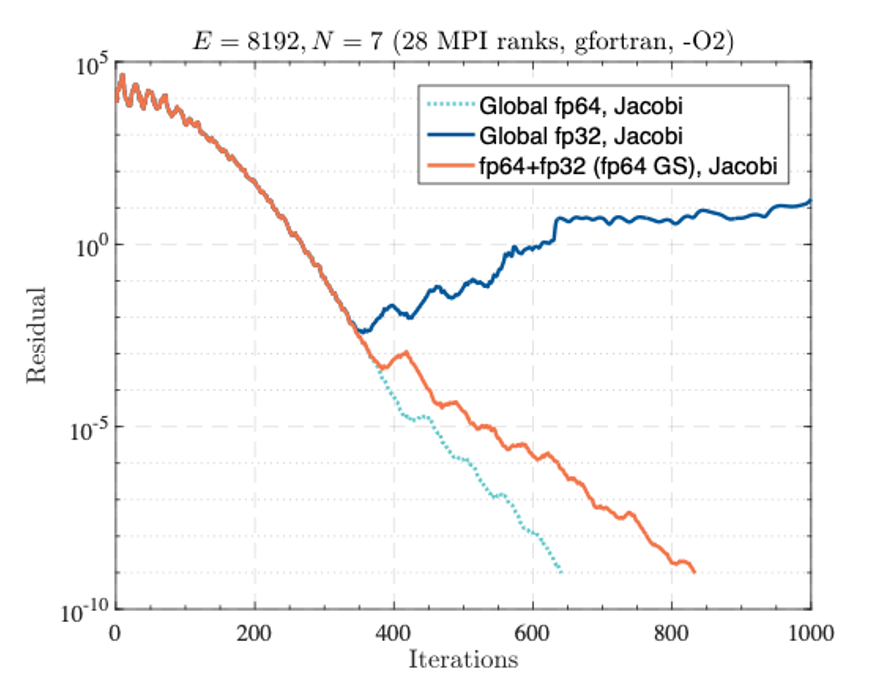
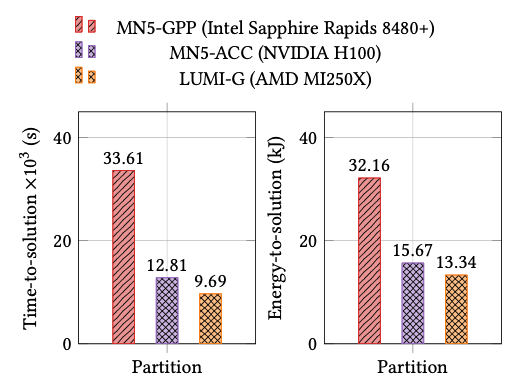
During the CEEC project, the GPU-accelerated high-order SEM code NekRS was employed to perform ultra-high-resolution Large Eddy Simulations (LES) for investigating both stable and convective (unstable) Atmospheric Boundary Layer (ABL) dynamics, collectively referred to asLHC5. For validation and model inter-comparison, the Global Energyand Water Cycle Experiment (GEWEX) Atmospheric Boundary LayerStudy (GABLS) benchmark was used to represent the stably stratified ABL. NekRS energy analysis using LLview on GPU-based systems shows that energy-to-solution scales proportionally with problem size when GPUs are efficiently utilized. High bandwidth efficiency enables excellent energy performance at scale, but underutilization due to communication overhead leads to rising energy ratios. The results underline that NekRSis primarily bandwidth- and communication-limited, and that maintaininghigh parallel efficiency is critical for sustaining energy efficiency in largescale LES simulations.
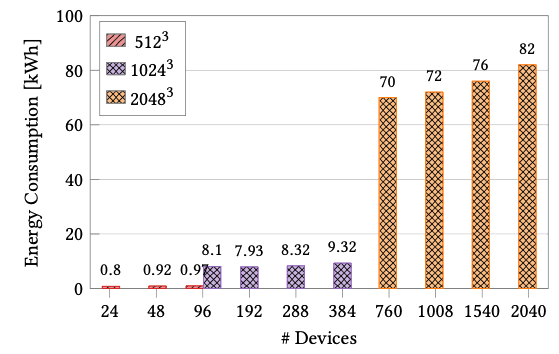
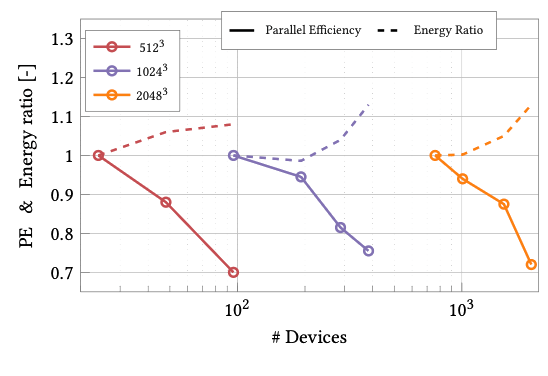
Conclusion
Porting CFD applications to GPUs, one of the goals of the CEEC project, demonstrated superior achievement of favorable energy-to-solution metrics compared to CPU-based systems. The application case studies within CEEC highlighted that our codes are well optimized and demonstrate exceptional scalability. However, the results also show that underutilization of computational resources can have detrimental effects on both performance and energy consumption. Furthermore, the adoption of mixed-precision techniques has been shown to provide an effective balance between computational accuracy and energy efficiency, representing a promising direction for sustainable exascale applications. The findings emphasize that optimization should not be limited to runtime reduction alone, but must equally consider the compute/storage precision and energy implications of numerical and architectural choices.
For further reading, check out our related publication: https://dl.acm.org/doi/10.1145/3784828.3785161